1
2
3
4





近日,清华大学电子工程系语音与音频技术实验室提出了一种端到端的基于注意力机制和能量评分器的关键词检索系统。该系统摆脱了语音识别的依赖,并且取得了超越传统方法的性能,尤其适用于低资源小语种关键词检索任务。
关键词检索即为在连续的语音流当中检测和定位用户给定的关键词的技术。在移动设备广泛应用、海量音视频源源不断产出的今天,关键词检索能有效提高信息检索的效率和多媒体资源的利用率。传统的关键词检索技术依赖于连续语音识别系统,即先使用语音识别系统得到识别结果(一般为多候选结果),然后再从识别结果之中寻找关键词并进行置信度估计。然而,训练出一个可靠的语音识别系统往往需要大量的标注语音数据,对于低资源语种,即可用的训练数据较少的语种,传统的方法往往会遇到一些困难。
为了解决低资源语种可训练数据少而制约关键词检索效果的问题,本工作采用的框架不再依赖于语音识别系统,大大降低对数据资源的依赖。以下是系统的整体结构框图:该系统主要由四部分组成,包括语音编码器(Speech Encoder),文本编码器(Query Encoder),注意力机制(Attention Mechanism)以及能量评分器(Energy Scorer)。
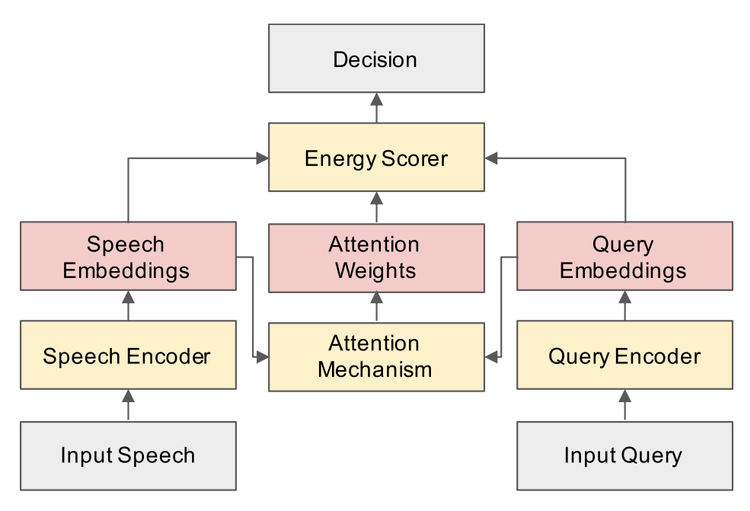
图1:端到端关键词检索系统的整体架构
语音编码器和文本编码器经过特殊设计,采用联结时序分类(Connectionist Temporal Classification, CTC)、基于注意力机制的序列到序列以及自监督训练等方法,使得生成的语音特征和文本特征包含关键词检索所需要的序列信息。其中,语音编码器结构如下图所示:
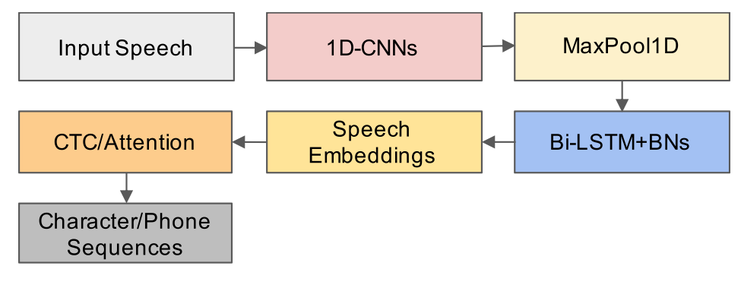
图2:语音特征提取过程以及使用联结时序分类或基于注意力的解码器从语音特征中预测字符或音素序列
然后,将语音和文本特征输入注意力机制和能量评分器,得到最终的评判结果。注意力机制和能量评分器,专门为关键词检测所设计,是本工作的两个重要创新点,也是超越传统方法的关键所在。图3演示了注意力权重在正负样本上的差异;图4是能量评分器的具体结构。
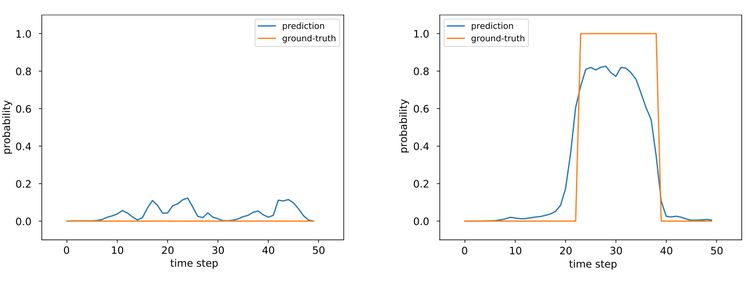
图3:负样本(左)和正样本(右)的注意力权重
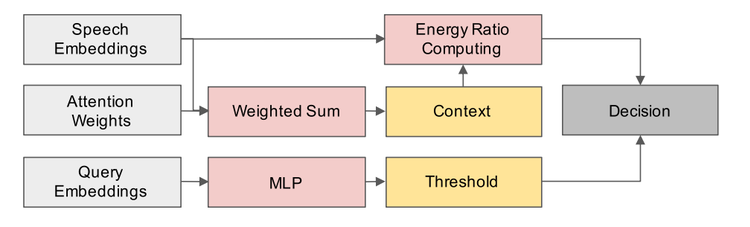
图4:能量评分器的结构
课题组首先根据注意力权重对语音特征进行加权求和从而得到上下文特征。接着,通过计算上下文特征和语音特征的能量比。最终,课题组将能量比和由文本特征经过多层感知机得到的门限进行比较从而得到最后的判决结果。
该系统有效解决了低资源小语种缺乏标注数据和专家知识所带来的制约,使得关键词检索技术在相关领域迈向实用。该论文发表于《神经网络》(Neural Networks),题为“基于注意力机制和能量评分器的端到端低资源语种关键词检索系统”(End-to-end keyword search system based on attention mechanism and energy scorer for lowresource languages),第一作者为清华大学电子工程系硕士研究生赵泽宇,通讯作者为其导师张卫强副研究员。
清华大学电子工程系语音与音频技术实验室近年来专注于低资源语音识别和关键词检索研究,主持国家自然科学基金联合重点项目和国家重点研发计划重点专项课题,2020年在美国国家标准与技术研究院(NIST)主办的语音分析评测OpenSAT2020关键词检索任务取得国际第一名,在OpenASR2020低资源语音识别挑战赛中十个低资源语种取得四个国际第一名。


